Where To Sell Products
Author: Luis Eduardo Ferro Diez contact@ohtar.mozmail.com
This repository contains all my work for my MsC in Computer Science project.
Where To Sell Products (wtsp) is a project in which I try to solve this very same question. The idea is to characterize geographic areas in terms of its relationship with a selected set of products. The relationship is derived from geotagged texts, i.e., I gathered geotagged text data from Twitter and product reviews from Amazon. For the former I generated spatial clusters from which all the tweets are aggregated to form a single cluster-corpus. For the latter I trained a convolutional neural network to classify product categories given several review texts. Finally each cluster-corpus is submitted to the classifier to emit a relevance score for some categories. The result is displayed on a map of an area of interest, e.g., a city, in which the clusters are shown with their corresponding relationship score with certain products categories.
Demo
Los Angeles (2013-07)
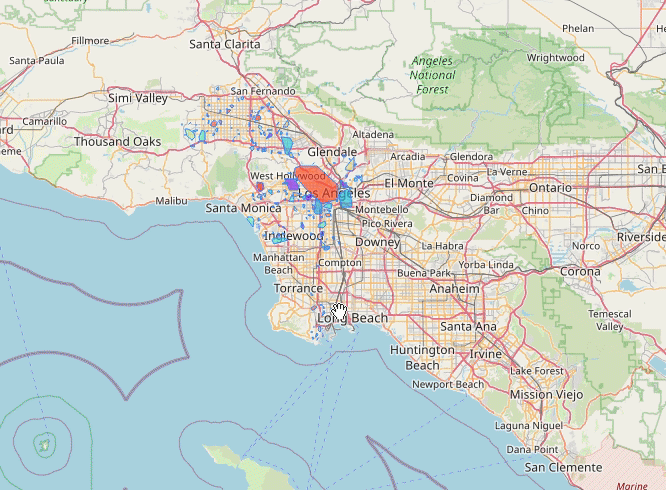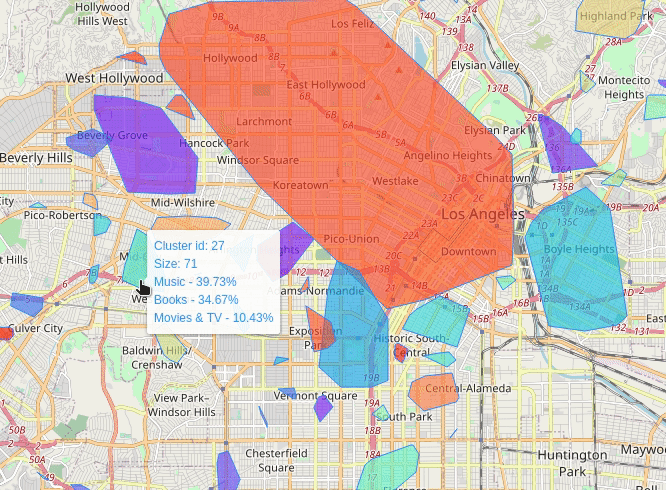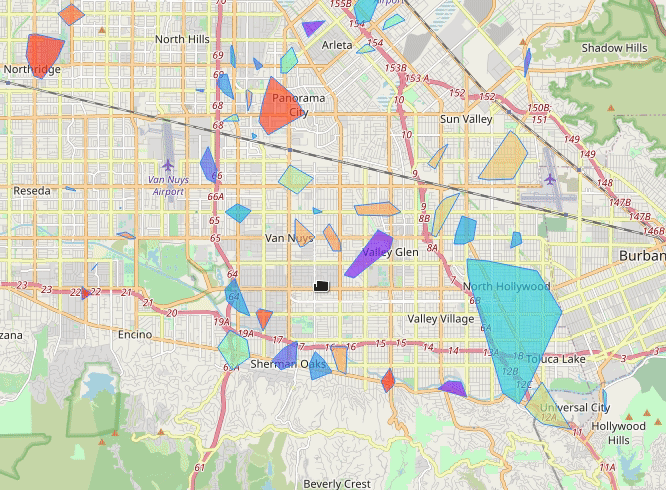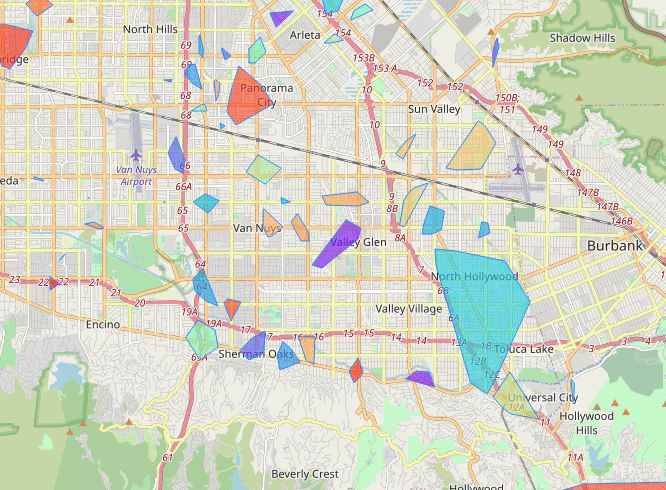
Vancouver (2013-07)
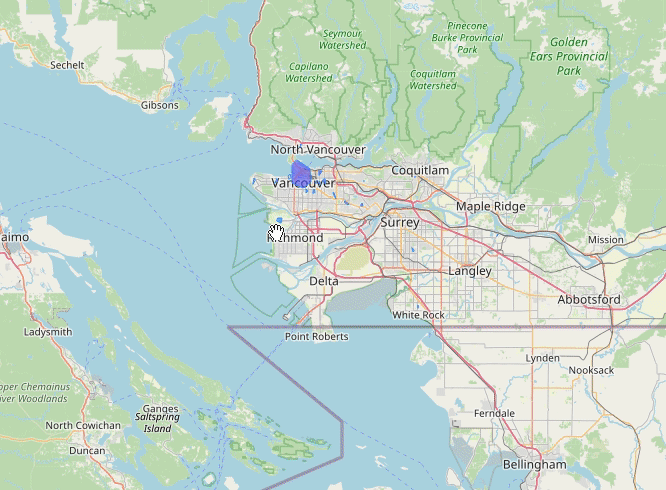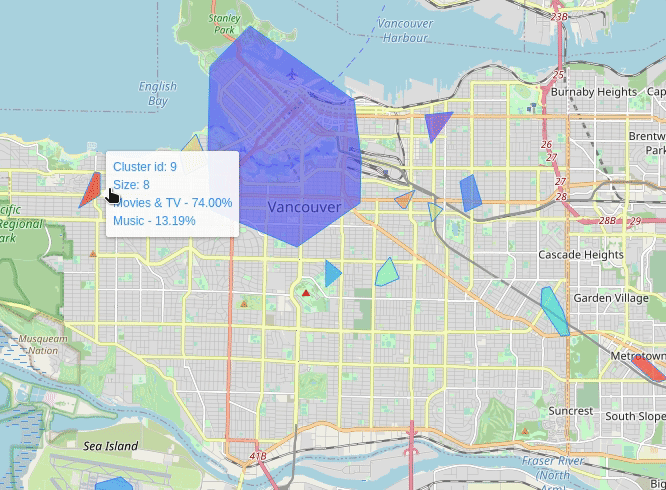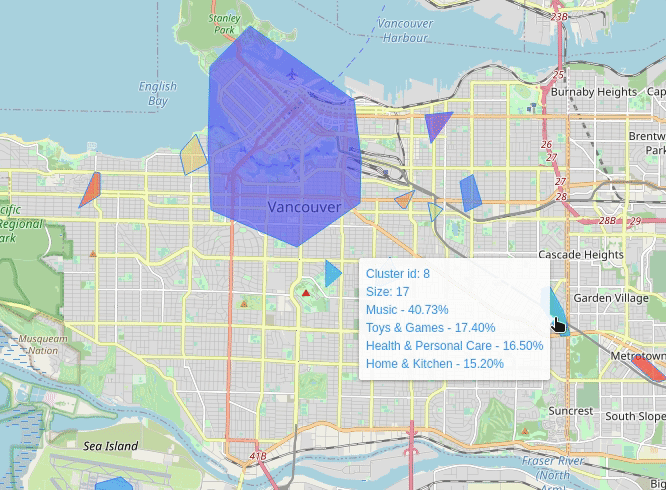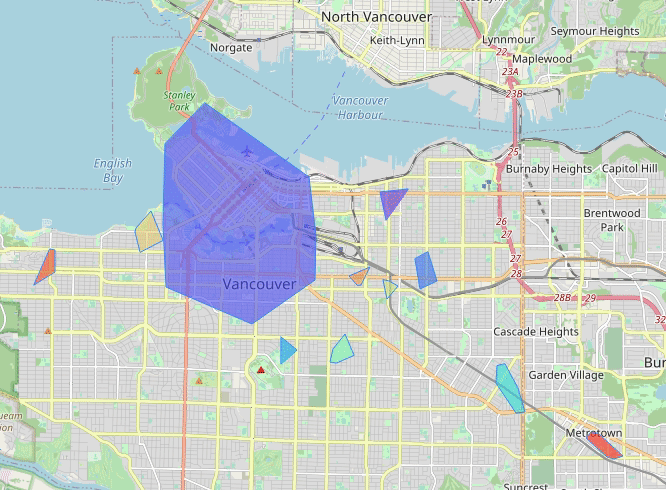
New York (2013-07)
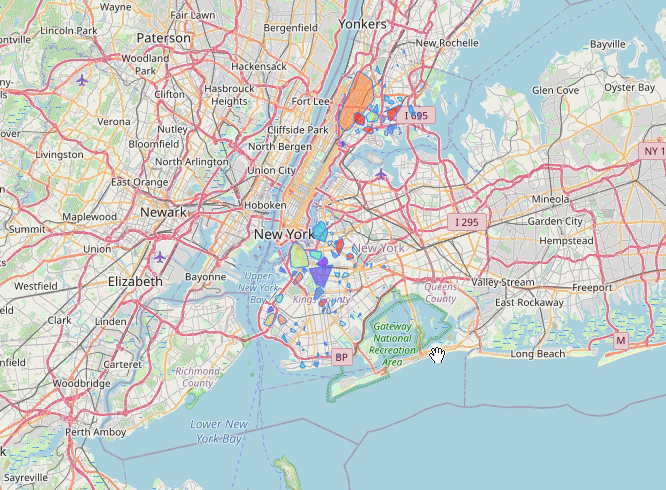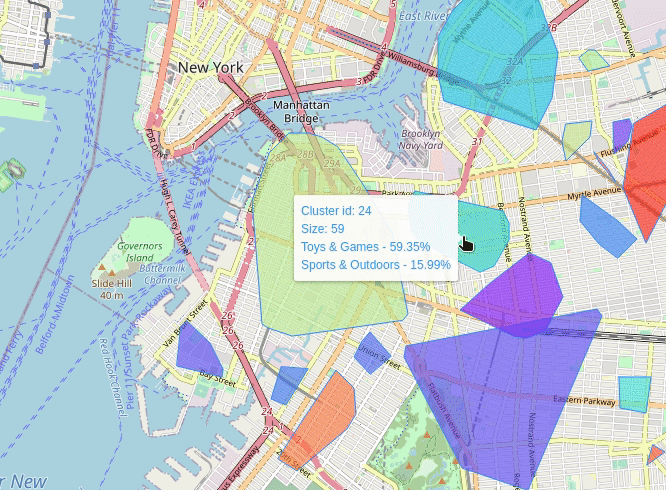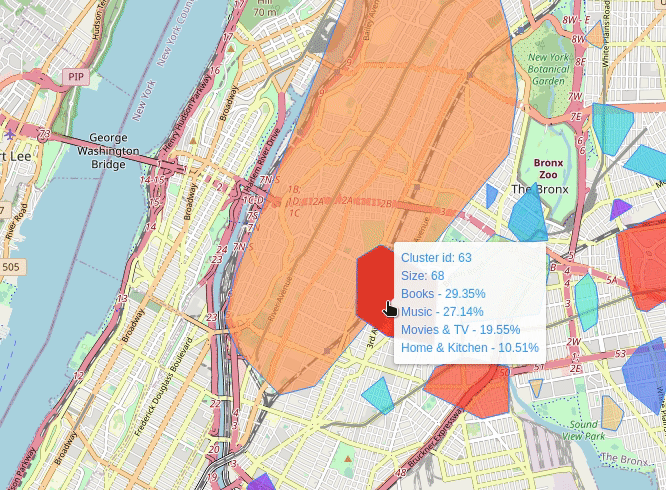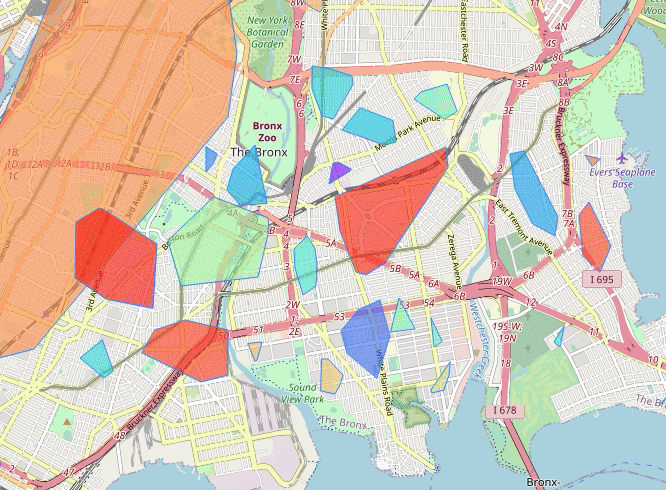
Live Demo
| City | Date |
|---|---|
| Los Angeles | June 2013 |
| Los Angeles | July 2013 |
| Los Angeles | August 2013 |
| Los Angeles | September 2013 |
| New York | June 2013 |
| New York | July 2013 |
| New York | August 2013 |
| New York | September 2013 |
| Vancouver | June 2013 |
| Vancouver | July 2013 |
| Vancouver | August 2013 |
| Vancouver | September 2013 |
| Toronto | June 2013 |
| Toronto | July 2013 |
| Toronto | August 2013 |
| Toronto | September 2013 |
Repository Structure
- Data Preparation (dataprep): It contains Apache Spark data engineering pipelines to prepare the raw sources for model training.
- Notebooks: It contains several notebooks with the plain experiments while developing the project, as well as a notebook showcasing the CLI usage.
- Runtime environments (env): It contains conda and docker environment configuration recipies and files.
System Requirements
- Java 1.8.x
- Apache Spark >= 2.3
- Conda >= 4.8.x
- Python 3.7.x
- CUDA 10.1
- Tensorflow 2.1.0
- Keras 2.3.1
Workflow
1. Gather the data
- Data from twitter can be obtained from https://archive.org here.
- Data from Amazon product reviews can be obtained here.
2. Execute the data preparation pipelines
Both twitter and product review data needs to be pre-processed, for this there are two spark projects under dataprep.
Tweets Transformer
This job takes the twitter data, filters out the tweets that are not geotagged and sinks the result as parquet files.
Amazon Product Reviews Transformer
This job takes the raw amazon product reviews and product metadata and converts them into ‘documents’ where each document has categories and either a review text or a product description.
3. Train the product classifier
Install the cli and follow the instructions to create the embeddings and train the classifier with the transformed product documents.
4. Predict the geographic area categories
Use the cli to predict the detect and classify the geographic areas.
Detailed process
A more detailed process is written in jupyter notebooks here
Results
Artifacts
We generated several artifacts that we made publicly available for further research, which can be downloaded from this link, the content is described as follows:
- dataset.zip: It contains the generated product document embeddings along with a sklearn category multilabel binarizer to decode the categories.
- d2v_model.zip: It contains the Gensim Doc2Vec model that can be used to generate new product document embeddings.
- classifier.zip: It contains the Keras model that classifies product documents. It also includes a sklearn category multilabel binarizer to decode the categories.
Usage
Product document embeddings
To load and use the generated product document embeddings:
Data
import numpy as np
embeddings_path = "/path/to/document_embeddings.npz"
embeddings = np.load(embeddings_path)
X_train = embeddings['x_train']
X_test = embeddings['x_test']
Y_train = embeddings['y_train']
Y_test = embeddings['y_test']
Label decoder
import numpy as np
from sklearn.preprocessing import MultiLabelBinarizer
import pickle
path = '/path/to/category_encoder.model'
with open(path, 'rb') as file:
categories_model = pickle.load(file)
categories_model.inverse_transform(np.array([[1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]))
Doc2Vec model
To load and use the Doc2Vec model to infer new document embeddings:
from gensim.models.doc2vec import Doc2Vec
from nltk import word_tokenize
from gensim.models.doc2vec import TaggedDocument
# Loading the model
model_path = '/path/to/d2v_model.model'
d2v_model = Doc2Vec.load(model_path)
# Inferring a new vector
paragraph = "I want to buy a big TV for my bedroom!"
tokens = word_tokenize(paragraph)
tag_doc = TaggedDocument(words=tokens, tags=['Technology'])
doc_embedding = d2v_model.infer_vector(tag_doc.words)
Product document classifier
To load and use the keras model to predict document categories:
from keras.engine.saving import model_from_yaml
base_path = '/path/to/classifier/files'
ann_def_path = f"{base_path}/prod_classifier-def.yaml"
ann_weights_path = f"{base_path}/prod_classifier-weights.h5"
with open(ann_def_path, 'r') as file:
prod_predictor_model = model_from_yaml(file.read())
prod_predictor_model.load_weights(ann_weights_path)
prod_predictor_model.summary()
Docker
I have created a docker image with a conda environment and cli pre-installed to execute the modeling part after the data engineering pipelines, and configured to run experments starting from pre-processed data https://hub.docker.com/r/ohtar10/wtsp.
The previously mentioned artifacts can be used with the docker image for prediction and characterization. After downloading the Doc2Vec and the classifier models, place them anywhere in your machine with the following structure:
workspace
└──products
└── models
├── classifier
│ ├── category_encoder.model
│ ├── classification_report.png
│ ├── prod_classifier-def.yaml
│ ├── prod_classifier-weights.h5
│ └── training_history.png
└── embeddings
├── d2v_model.model
├── d2v_model.model.trainables.syn1neg.npy
└── d2v_model.model.wv.vectors.npy
Next, download the docker image from docker hub:
docker image push ohtar10/wtsp:0.1.1
Then, you can use the this docker-compose file as template to start the container. Remember to set the environment variable WORK_DIR to the root folder of the workspace folder mentioned above. And start the container:
docker-compose up
Finally, ssh into the container and start using the cli
wtsp --help
wtsp predict clusters --filters "place_name=Toronto,country_code=CA" --params center='43.7;-79.4',eps=0.005,n_neighbors=10,location_column=location_geometry,min_score=0.1 /path/to/preprocessed/twitter/data/
Acknowledgements
This work could have not been done without the help and guidance of my advisors: Dr. Norha M. Villegas, and Dr. Javier Díaz Cely, whom I owe my utmost gratitude.
License
GNU GENERAL PUBLIC LICENSE Version 3, 29 June 2007
See the LICENSE_ file in the root of this project for license details.